Transcribing audio with OpenAI Whisper on AWS Lambda
Want to build AI-powered voice applications? Learn how to upload audio from a smartphone, processing it with FFmpeg, and transcribing voice to text with OpenAI’s Whisper model.

Want to build AI-powered voice applications?
The Whisper model by OpenAI is great for transcribing voice into text – even supporting multiple languages. It supports a variety of audio formats like FLAC, MP3, MP4, MPEG, MPGA, M4A, OGG, WAV, WEBM.
Unfortunately, typical audio uploads from smartphones are often in CAF format for iOS, or 3GP for Android. Whisper will respond with “Invalid file format. Supported formats: ['flac', 'm4a', 'mp3', 'mp4', 'mpeg', 'mpga', 'oga', 'ogg', 'wav', 'webm’]”.
To overcome this, we need to convert the audio first. This means we have to package FFmpeg, a full Linux binary, with our backend code.
Luckily, AWS Lambda serverless functions supports this.
Creating the Lambda function
I like to have a [MY_PROJECT]/lambda folder, where each Lambda function gets its own subfolder. This is how this transcribeAudio function is organized:
📁 [MY_PROJECT]/lambda/transcribeAudio
∟ 📁 bin
∟ 📄 ffmpeg // this is the FFmpeg binary
∟ 📄 index.js // main function handler
∟ 📄 package.json
∟ 📄 yarn.lock
∟ 📁 node_modules
Writing the Lambda function handler
The code inside index.js:
const ffmpeg = require('fluent-ffmpeg')
const OpenAI = require('openai')
const fs = require('fs')
const path = require('path')
module.exports.handler = async (event) => {
try {
// Initialize FFmpeg
const ffmpegPath = path.join(__dirname, './bin/ffmpeg')
ffmpeg.setFfmpegPath(ffmpegPath)
// Assume audio data POSTed as base64
const { audioFormat = 'mp4', audioData } = JSON.parse(event.body)
if (!audioData) throw new Error('No audio data provided')
// Save audio to temporary storage in Lambda
const inputPath = `/tmp/input.${audioFormat}`
const outputPath = '/tmp/output.mp3'
const audioBuffer = Buffer.from(audioData, 'base64')
fs.writeFileSync(inputPath, audioBuffer)
// Convert audio to MP3
await convertToMp3(inputPath, outputPath, audioFormat)
// Use OpenAI Whisper to transcribe audio
const readStream = fs.createReadStream(outputPath)
const text = await getAudioTranscription(readStream) ?? ''
// Return results
return {
statusCode: 200,
body: JSON.stringify({ text })
}
} catch (err) {
// Handle error
return {
statusCode: 500,
body: JSON.stringify({ message: `Server error: ${err.message}` })
}
}
}
const convertToMp3 = async (inputPath, outputPath, inputFormat = 'mp4', outputFormat = 'mp3') => {
return await new Promise((resolve, reject) => {
ffmpeg(inputPath)
.inputFormat(inputFormat)
.output(outputPath)
.outputFormat(outputFormat)
.on('end', () => {
resolve()
})
.on('error', (err, stdout, stderr) => {
console.error('* FFmpeg error:', err.message)
console.error('stdout:\n' + stdout)
console.error('stderr:\n' + stderr)
reject(err)
})
.run()
})
}
// FLAC, MP3, MP4, MPEG, MPGA, M4A, OGG, WAV, WEBM
// Expo: CAF for iOS, 3GP for Android
const getAudioTranscription = async (readStream) => {
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY })
const transcription = await openai.audio.transcriptions.create({
file: readStream,
model: 'whisper-1'
})
return transcription.text
}
Getting the FFmpeg binary
In [MY_PROJECT] root folder, I did this:
mkdir ffmpeg-temp && cd ffmpeg-temp
wget https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-amd64-static.tar.xz
tar xvf ffmpeg-release-amd64-static.tar.xz
mkdir -p lambda/transcribeAudio/bin
cp ffmpeg-6.0-amd64-static/ffmpeg ../lambda/transcribeAudio/bin
cd ..
Deploying the Lambda function to AWS
You can upload a ZIP file with your Lambda function to the AWS web console, but an easier way is to use the AWS command-line tool.
So in [MY_PROJECT] folder, I did this:
cd lambda
echo Creating ZIP archive...
rm transcribeAudio.zip
cd transcribeAudio && zip -r ../transcribeAudio.zip * && cd ..
echo Uploading to AWS Lambda...
aws lambda update-function-code --function-name transcribeAudio --zip-file fileb://transcribeAudio.zip
cd ..
Tip: put these commands in the scripts section in package.json, so you can run:
yarn lambda-deploy # Deploy Lambda function to AWS
yarn lambda-ffmpeg # Get latest FFmpeg
Connecting a REST API to the Lambda function
Lambda functions can be used for cron jobs etc, but AWS also provides an easy way of wrapping it in a REST API: the API Gateway.
Go to your Lambda function on AWS Console, and press the “Add trigger” button to set it up:
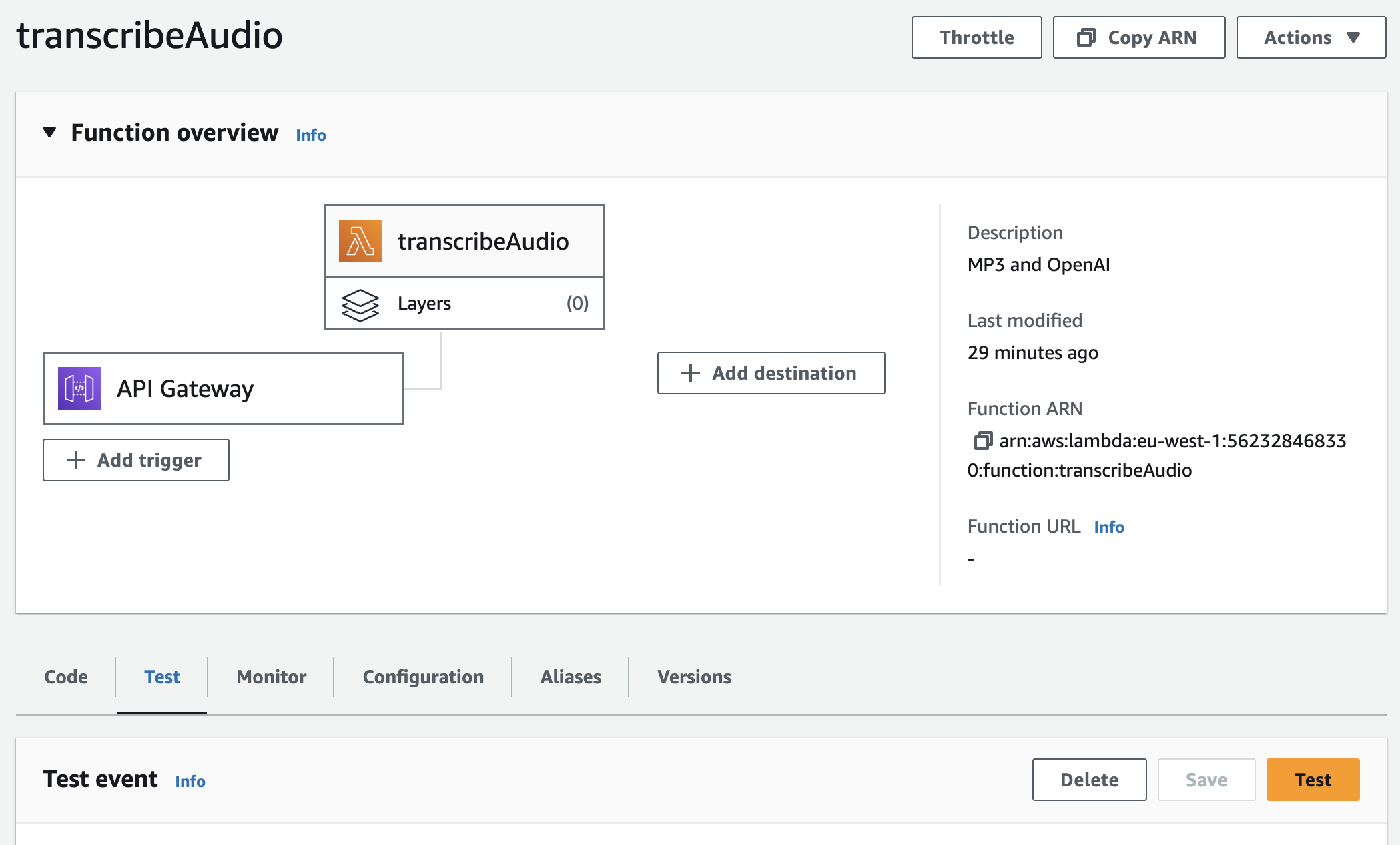
You will then get a long URL that you can use to POST your data to.
More
Configuration
- You will most likely need to increase the timeout of your Lambda function to 1-2 minutes (default: 3 seconds), see the “Configuration” tab on your Lambda’s page on AWS Console.
- You can enter environment variables, e.g. your secret OpenAI API key, again see the “Configuration” tab.
Testing & debugging
- AWS Lambda has a built in tool for testing your function, see the “Test” tab on your Lambda’s page.
- Note: when using a real client, the
POST:ed data will come inevent.bodyas a string, not an object like the Test tab provides. - Detailed logging (including
console.logstatements) is captured in AWS CloudWatch. A shortcut is found if you use the Test feature mentioned above.